대가(return)
시간 t에서 대가(return)는 에피소드 전체 기간을 통해 얻은 누적된 보상이다.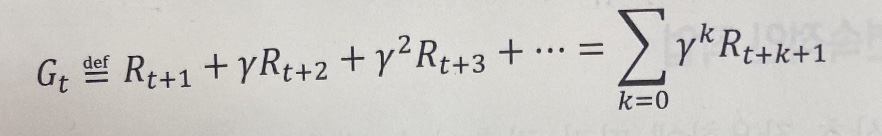
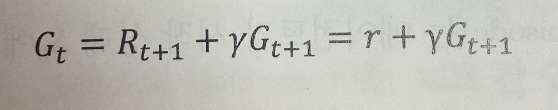
R_t+1=r은 시간 t에서 행동 A_t를 수행한 후 얻은 즉각적인 보상이다.
시간 t에서의 대가는 위와 같이 즉각적인 보상과 이후의 보상을 합하여 계산할 수 있다.
감마는 [0, 1] 사이 범위를 가지는 할인 계수(discount factor)이다.
(미래 보상이 현재 시점에서 얼마나 가치 있는지를 나타낸다.)
할인 계수가 0이라면 미래 보상에 관심이 없다는 의미이다.
t+1 이후의 보상을 무시하기 때문에 즉각적인 보상과 같아진다.
할인 계수가 1이라면 대가는 가중치를 적용하지 않고 모든 미래 보상을 더한 값이 된다.
정책(policy)
정책은 다음에 선택할 행동을 결정하는 함수로 결정적일 수도 있고 확률적일 수도 있다.
(확률적 정책은 주어진 상태에서 에이전트가 선택할 수 있는 행동에 대한 확률 분포를 가짐)
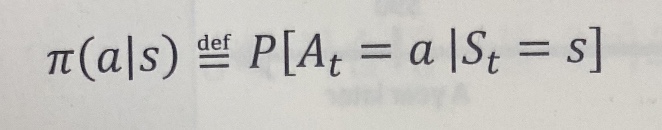
학습 과정동안 에이전트가 더 많은 경험을 얻으며 정책이 바뀔 수 있다.
처음에는 모든 행동의 확률이 균등하게 랜덤한 정책으로 시작해서
에이전트는 최적의 정책에 가깝게 되도록 정책을 학습한다.
최적의 정책은 가장 높은 대가를 만드는 정책을 말한다.
가치 함수(value function), 상태-가치 함수(state-value function)
각 상태의 좋음을 측정한다.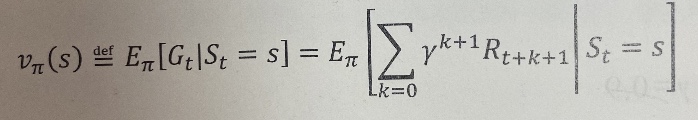
(특정 상태가 얼마나 좋은지 또는 나쁜지를 측정, 기존은 대가를 기반)
상태 s의 가치 함수를 정책 pi를 따른 후 (모든 에피소드에 걸친 평균 대가인)) 대가 G_t의 기댓값으로 정의
실제 구현에서 일반적으로 룩업 테이블을 이용해서 가치 함수를 추정한다.(다시 계산할 필요가 없음, 동적 계획법 특징)
(모든 상태 가치 V(s)를 테이블에 저장)
행동-가치 함수(action-value function)
상태-행동 쌍에 대한 가치를 정의할 수 있다.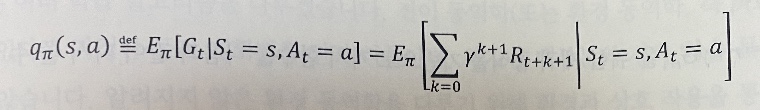
행동-가치 함수는 에이전트의 상태 S_t=s이고 선택한 행동 A_t=a 일 때, 기대 대가 G_t를 의미한다.
가치함수를 추정하는 것이 강화 학습 도구들의 핵심 요소이다.
보상 & 대가 & 가치함수
보상은 에이전트가 현재 환경의 상태에서 선택한 행동의 결과물이다.
(에이전트의 상태를 전이하기 위한 행동에 따른 에이전트가 받는 신호)
체스 같은 경우 게임에서 승리한 후에만 보상을 받는다.(중간의 모든 행동에 대한 보상은 0)
상태 자체는 어떤 값을 가진다. 이를 이용해서 상태를 측정하기 위해서 가치함수가 필요하다.
일반적으로 높거나 좋은 가치를 가진 상태는 높은 기대 대가를 가진 상태이다.
체스에서 퀸을 잡았을 경우(이득을 보았을 경우), 즉각적으로 받는 보상은 없다.
하지만, 높은 가치를 가질 수 있다.(높은 가치는 게임의 승리와 연관이 있다.)
(양의 보상을 받을 가능성이 있지만, 보장이 되지는 않는다.)
대가는 전체 에피소드에 대한 보상의 가중치 합
체스의 경우 할인된 최종 보상과 같다.
가치 함수는 가능한 모든 에피소드에 대한 기대치이다.
어떤 행동을 수행하는 것이 평균적으로 얼마나 가치가 있는지 계산한다.